Spark¶
About Apache Spark¶
Apache Spark is a unified analytics engine for large-scale data processing. Basically, it’s a cluster computing framework offering a stack of libraries for SQL and data frames (Spark SQL), machine learning (MLIib), graphs (GraphX) and streaming (Spark Streaming).
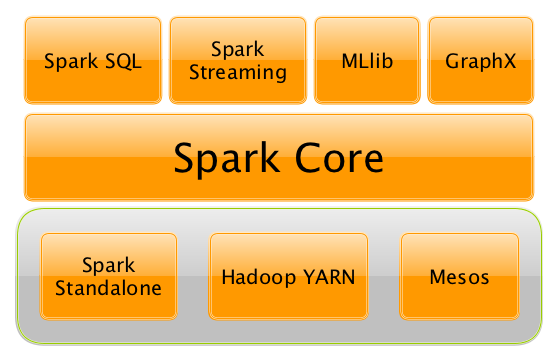
Although, Spark is written in Scala, applications can also be submitted in Java, Python, R and SQL. Spark can either be run in its standalone cluster mode or on EC2, on Hadoop Yarn, Mesos or on Kubernetes.
Comparing Apache Spark with Apache Hadoop¶
Apache Spark differs from Apache Hadoop in their different approaches to processing. Spark is able to do it in-memory, whereas Hadoop’s MapReduce has to read from and write to a disk. As a result, the processing speed differs significantly. Commonly, Spark is said to be up to 100 times faster.
However, the volume of data processed also differs: Hadoop’s MapReduce is able to work with far larger datasets than Spark. Incase the dataset is larger than available RAM, Hadoop MapReduce may outperform Spark. Due to Hadoop’s worse performance, it should only be used if no immediate results are expected e.g. if processing can be done overnight. Spark’s iterative processing approach is especially useful, when data is processed multiple times. Spark’s Resilient Distributed Datasets (RDDs) enable multiple map operations in memory, while Hadoop MapReduce has to write interim results to a disk.